
Using student data to predict if a student will finish an online course.
Overview
We were given a set data about student activity in a particular college course. The goal was to use this data to predict whether the student would finish the course. There were four steps to achieving this goal. First, we needed to choose the best features using a validation set. Then we needed to train the model and try three different classifiers with various parameters. We wanted to find the most accurate model, therefore we needed to find a way to get the best parameters. Finally, we needed to test our model on a set of test data. This project was a Kaggle competition between our classmates to build the most accurate model so it we needed to learn how to work as a team in order to win!
Choosing Features
The features we chose were decided based on which variables we thought would make an actual impact on performance of a student. For example, the number of posts they make in a discussion forum indicates level of participation in the class and therefore we would want this included in our model. Unlike "start date" which would probably tell us nothing about the student, other than if they started the class late so we decided to not include this in our model. We transformed the YoB (year of birth) variable from object to numeric type so that it would be easier to work with in our model. We also hot encoded all of our chosen categorical features.
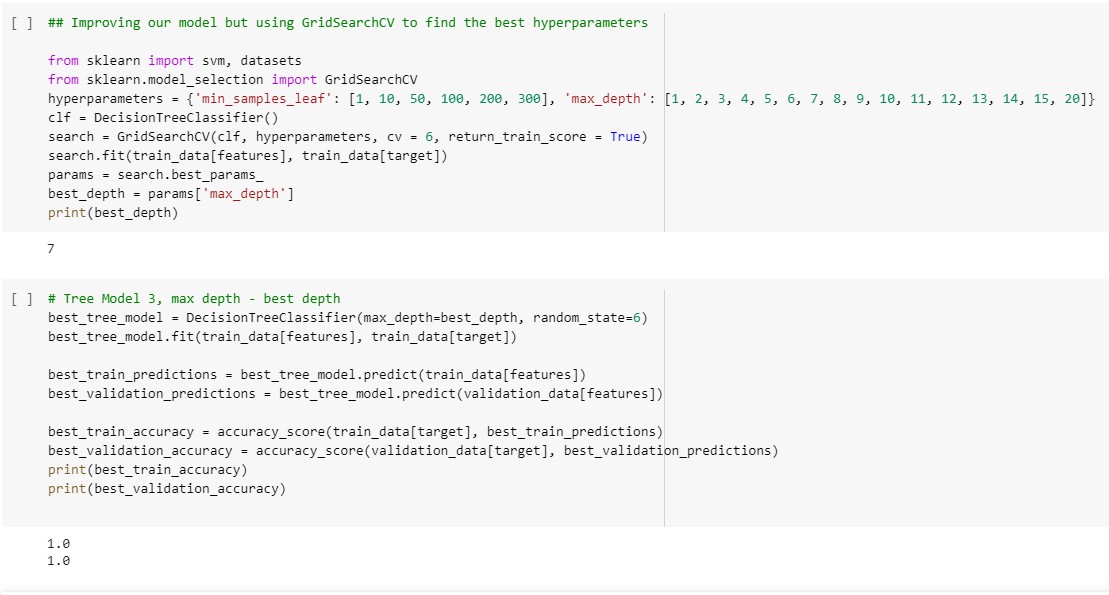
Training the Model & Finding Best Hyperparameters
We first built two decision tree classifier models with arbitrary max depths. They achieved satisfactory accuracy (click button bellow to see the code for our first models) but we wanted the best hyperparameters. To find these parameters we used GridSearchCV to find the depth that gave the highest accuracy. GridSearchCV found that the best depth is 7 for our model. It is important that our model is not too complex so that it fits a variety of data rather than just to our dataset. Applying this depth to our model gave us a validation accuracy of 100%. Although this doesn't mean we will get 100% on all testing data, it does show that our model is very good at predicting student completion.
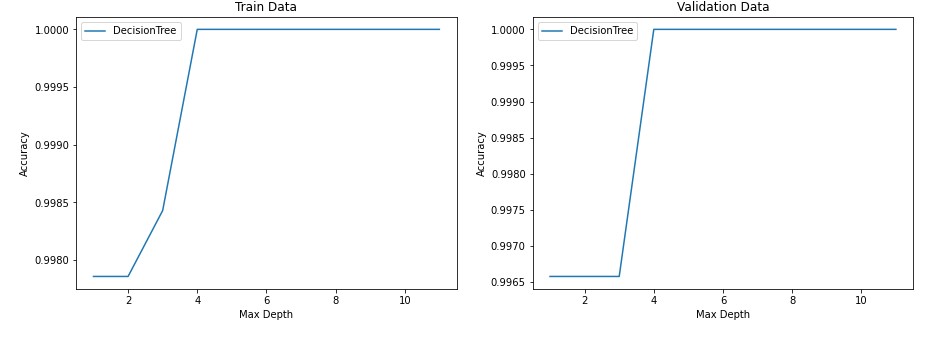
Additional Testing
We also used our model on a different set of data, please see full code for the results. This was submitted to our competition in which we placed in the top 3. We also created a data visualization of different depths on our training and testing data. The graph on the left shows our training accuracy score and graph two shows our validation accuracy score. As you can see, the training score grows as it increases until it hits a plateau at a depth of 4 for 100%. This would be concerning for overfitting, however our validation accuracy follows the same trend. From this, we can infer that our data likley has a strong predictor of certification and that around a depth of 4 variable decscion nodes it can make a very accruate prediction. We can also infer that if we use a depth much larger than 4 we will likely have an overfitted model; even though the accruacy score in the graph shows 100% at all depths higher than 4 it does not neccessarily translate the same to future data.

Ethical Implications
When considering the ethical implications of classifying students into online learning programs, both bias and fairness need to be taken into account. The company should recignize the tradeoff that often occurs between model accuracy and fairness. The overall goal of the model is to maximize profits by tailoring course material to get more people to sign up. However, it is important to consider the prejudice and bias that comes along with the goal of only maximizing profits. The company should consider how highly they value their customers representing the demographics of the overall population. Gender and ethnicity can often correlate with the odds of one's educational success, so it is important to know how heavily these factors are weighted when training the data.
The failure to take into account the education performance of underrepresented populations is a result of historical bias, which means that even accurate data could stil be harmful. In addition to historical bias, representation bias may occur based on only collecting data from students that have the resources to access online education services. To address these biases the company needs to be clear and transparent about how the data is collected, and what variables are being used for their model's deciaion making.
About Me
I am a recent graduate from the University of Washington. I studied Geographic Information Systems with a focus in Data Science. My data science passions include sports analytics (ask my about my fantasy football strategy) and Machine Learning. Outside of programming I love to hike, run ultramarathons and cook! Please reach out to me via email or LinkedIn if you have any questions.